
Kuvallisen kielen ymmärtäminen AI-kielimallien avulla

GPT-4 kielimalli on osoittanut jo poikkeuksellisia moniulotteisia kykyjä tekoälyn suhteen. Esimerkkeinä verkkosivujen luonti suoraan käsinkirjoitetusta tekstistä kuvamuodossa tai humorististen elementtien tunnistaminen kuvista.
Vastaavia kykyjä on harvemmin havaittu aikaisemmissa kuva-kielimalleissa (vision-language models). Ilmiön tutkimista ja esittelyä varten on perustettu MiniGPT-4.
MiniGPT-4 auttaa tulkitsemaan kuvia ja muodostamaan niistä kirjallisen selityksen tarpeen mukaan. Alla muutama esimerkki ja lisää voit tutkia Githubin MiniGPT-4 osiosta.
Esimerkkejä
Kirjoita HTML/JS muodossa kuvasta verkkosivu:

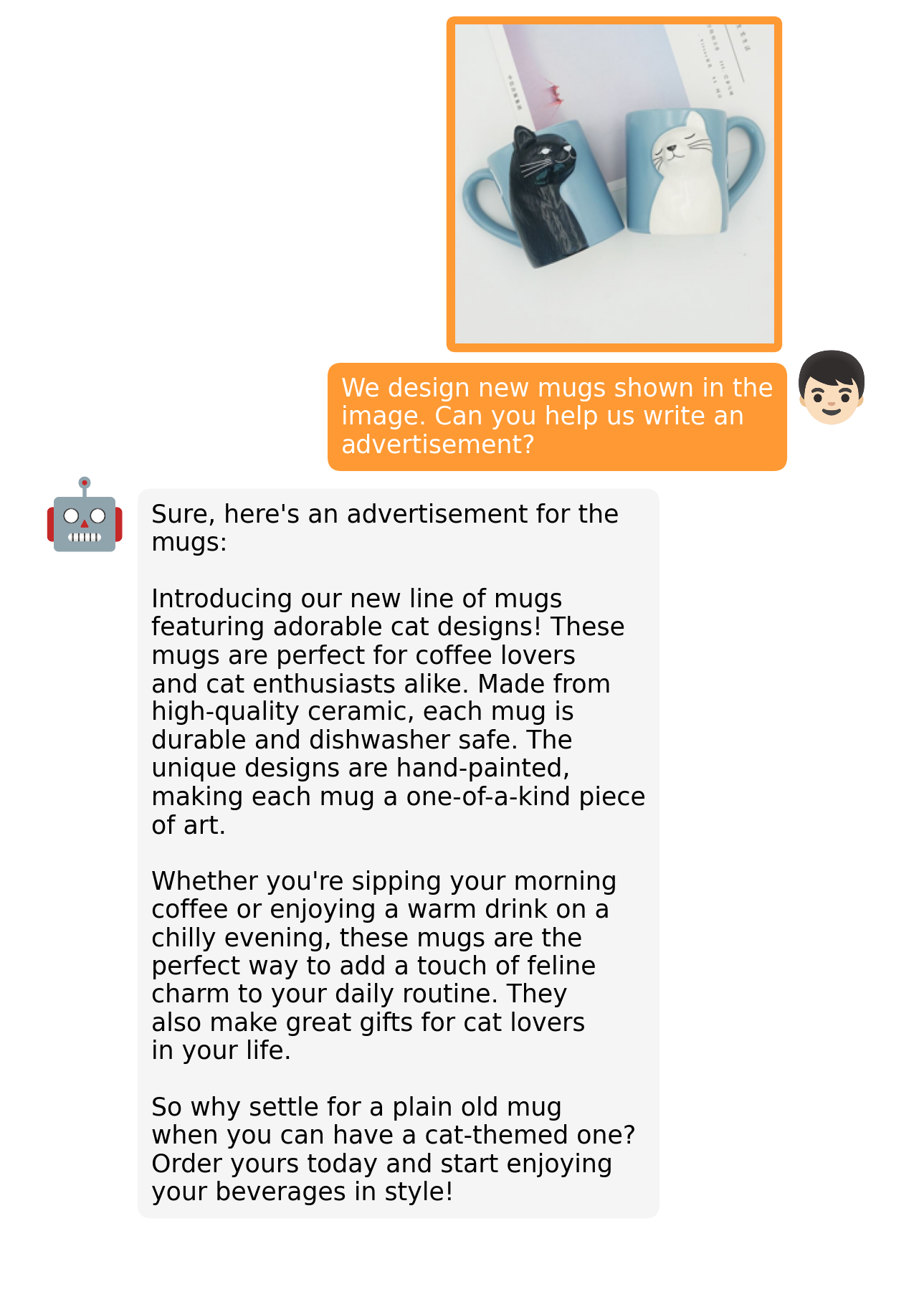
Kirjoita kuvasta mainos:
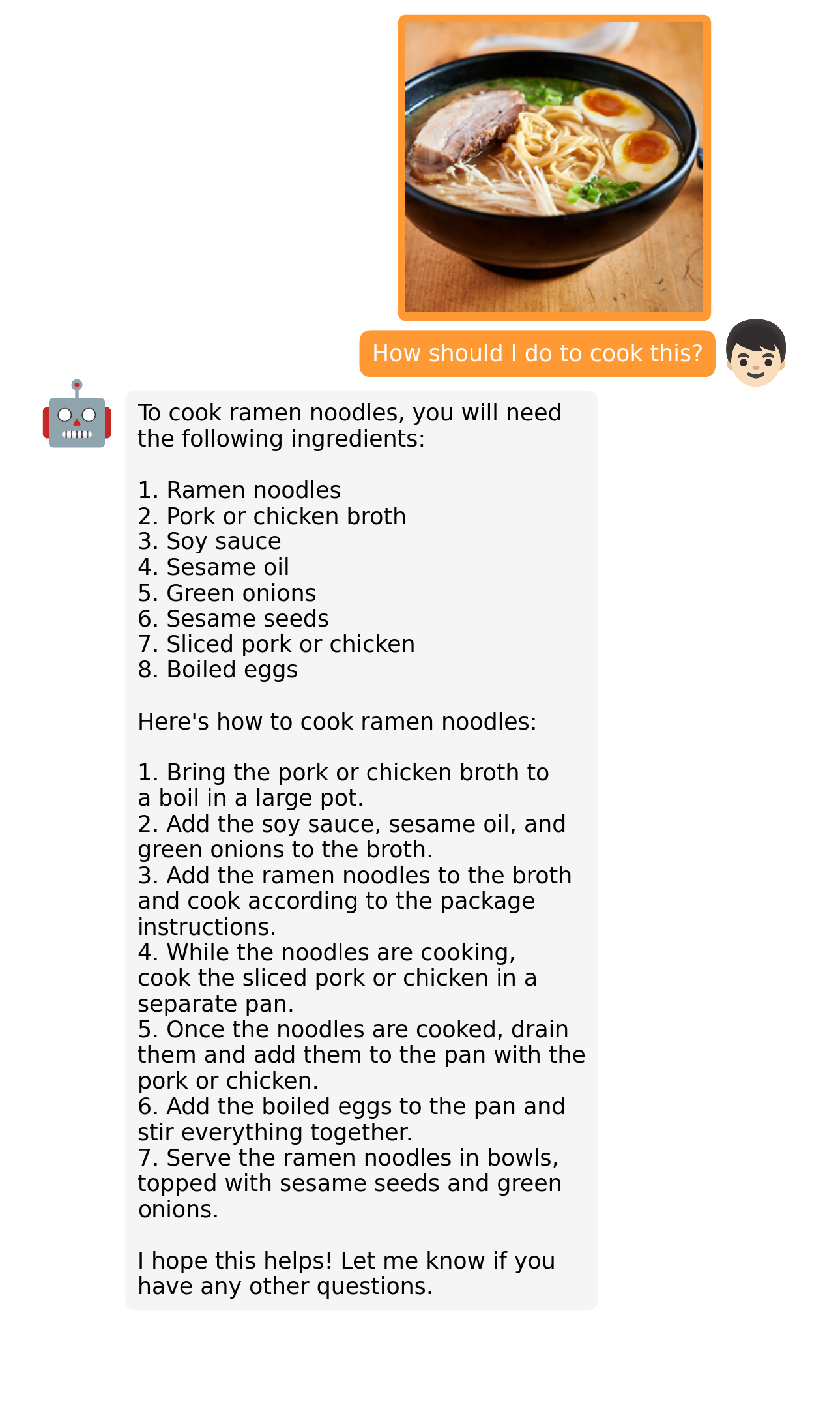
Kirjoita kuvan perusteella resepti ja ohjeet sen valmistamiseen:
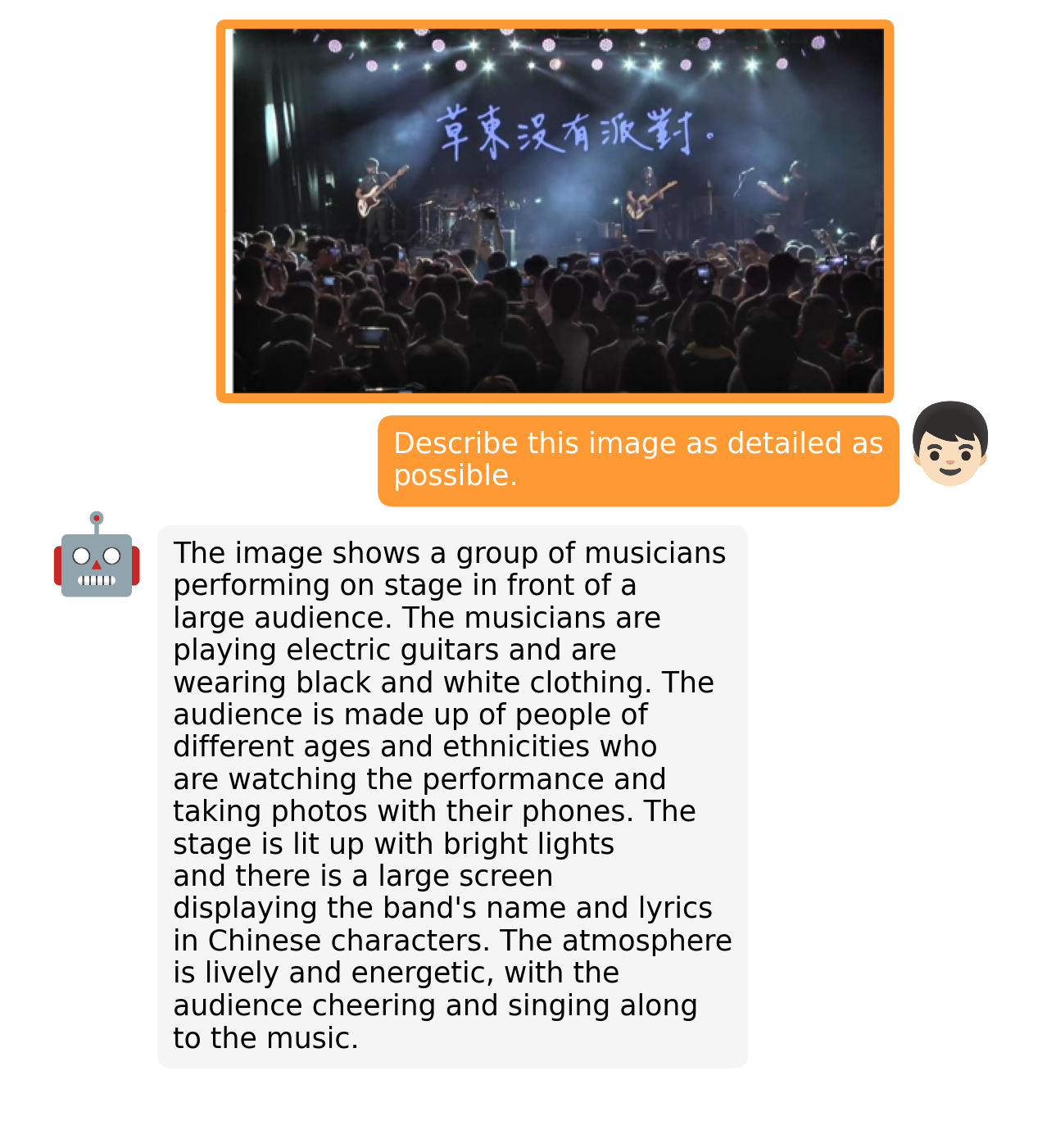
Kuvaile mahdollisimman tarkasti, mitä kuvassa näkyy:
Miten malli toimii?
MiniGPT-4 koostuu visuaalisesta kooderista (visual encoder), jossa on esikoulutettu ViT ja Q-Former, yksi lineaarinen projektikerros sekä avoimen lähdekoodin laaja kielimalli Vicuna.
Mikäli haluat opiskella tekoälyä enemmän, tutustu ilmaisten AI-koulutusten tarjontaan täältä.



{kind=link}
{kind=link}
{kind=link}